SQL - ORDER BY / GROUP BY / HAVING / 집합 연산자
ORDER BY
- Result set에 대한 정렬
- SELECT 구문의 마지막에 작성
- ASC : 오름 차순 / DESC : 내림 차순
- 생략 시 오름 차순으로 정렬
SELECT 컬럼명
FROM 테이블명
WHERE 조건식
ORDER BY [컬럼명] [ASC / DESC] [NULLS FIRST / NULLS LAST];
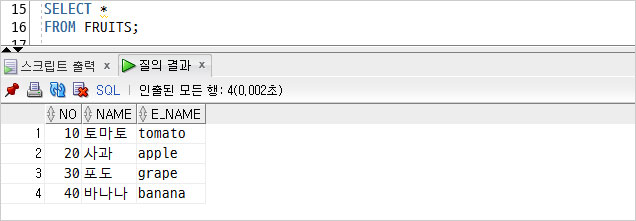
FURITS 테이블을 조회한 모습이다.
-
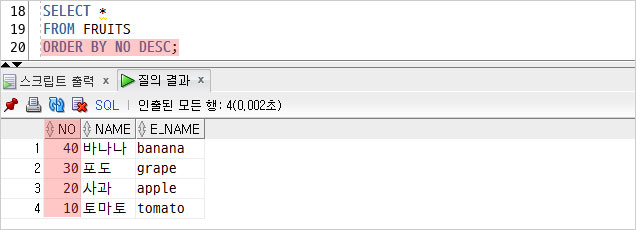
FURITS 테이블을 조회할 때 [DESC]를 이용하여
‘NO’를 내림차순으로 조회한다.
-
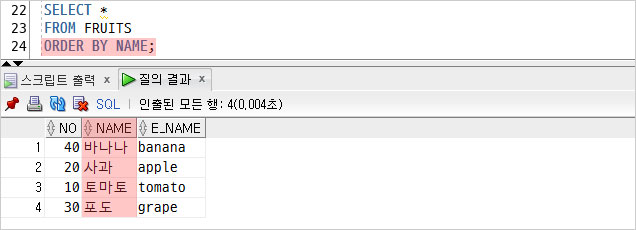
이번엔 과일의 한글을 기준으로 정렬했다.
가나다 순으로 조회되는 것을 볼 수 있다.
반대로 정렬하고 싶을 경우 DESC를 사용하면 된다.
-
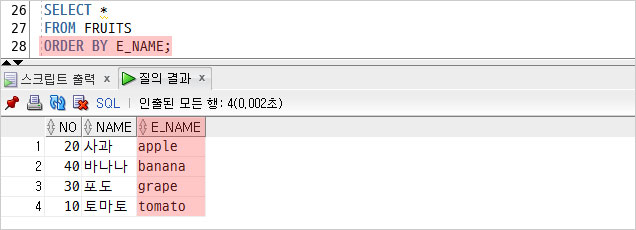
이번엔 알파벳 순으로 조회한 모습!
-
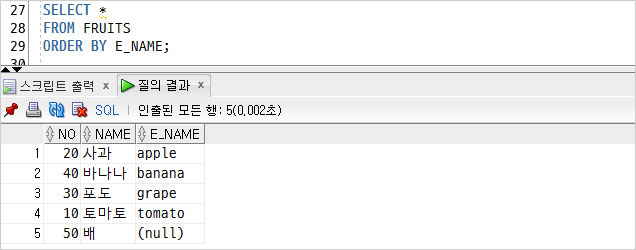
컬럼을 하나 추가했고, 한글이름은 ‘배’, 영어이름은 NULL로 지정했다.
NULLS FIRST / NULLS LAST를 테스트 해 볼 것이다.
이 두 옵션은 NULL 값이 있을 때의 정렬 방식을 지정한다.
NULL값은
오름 차순일 때는 마지막에 조회
내림 차순일 때는 처음에 조회된다.
E_NAME 정렬 시, NULL에 대한 정렬 옵션을 지정하지 않았기 때문에
NULL이 제일 마지막 행에 조회된다.
-
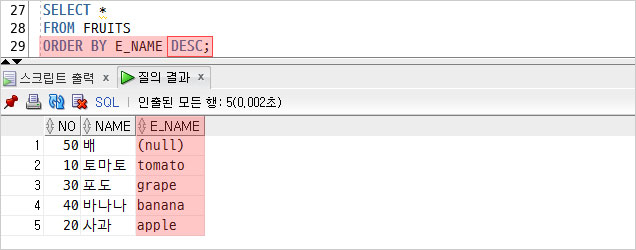
내림 차순으로 정렬할 경우 NULL이 제일 먼저 조회되는 것을 볼 수 있다.
GROUP BY
- 여러 개의 값을 하나의 그룹으로 묶어서 조회
- 그룹 함수는 한 개의 값만 산출하기 때문에 그룹이 여러 개일 경우 오류 발생
- 여러 개의 결과 값을 산출하기 위해 그룹 함수가 적용될 그룹의 기준을 GROUP BY절에 기술하여 사용
- 순번, 별칭 사용 불가
SELECT 컬럼명
FROM 테이블명
GROUP BY 그룹으로 사용 할 컬럼명;
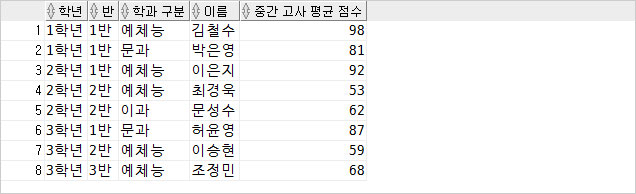
이런 테이블이 있을 때 GROUP BY 절을 이용하여 사용해 볼 예정이다.
-
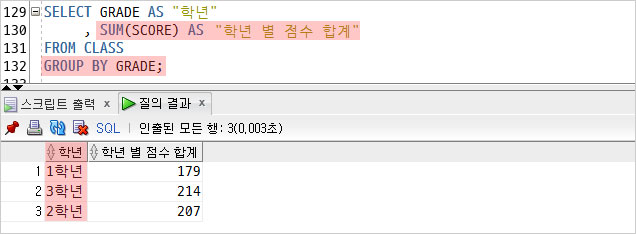
1) 학년 별로 그룹을 만들고
2) 학년 별 점수의 합계를 조회했다.
이 때, SUM(그룹 함수)은 하나의 결과만 조회하기 때문에
GROUP BY 절에 학년을 기술하여 사용하였다.
이거 설명하기 약간 힘드네…
-
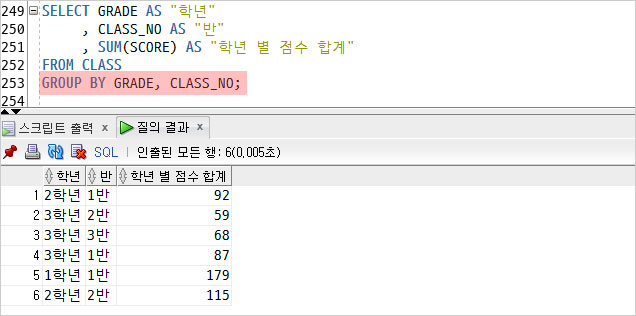
여러 개의 그룹을 지정할 수도 있다.
HAVING
- GROUP BY 절에 대한 조건 설정
- WHERE 절은 SELECT에 대한 조건 설정(헷갈리지마)
SELECT 컬럼명
FROM 테이블명
GROUP BY 그룹으로 사용 할 컬럼명
HAVING 그룹 조건;
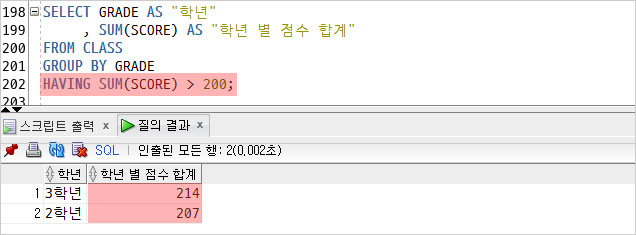
위에서 조회한 결과에 HAVING 절을 추가했다.
학년 별 총점이 200점이 넘는 행만 조회한다.
GROUP 에 대한 조건은 꼭 HAVING으로 할 것!
ROLLUP
- 그룹 별 합계 반환
- 가장 먼저 지정한 그룹 별로 추가 집계 결과 반환
SELECT 컬럼1, 컬럼2, ...
FROM 테이블명
GROUP BY ROLLUP(컬럼1, 컬럼2, ... 컬럼N);
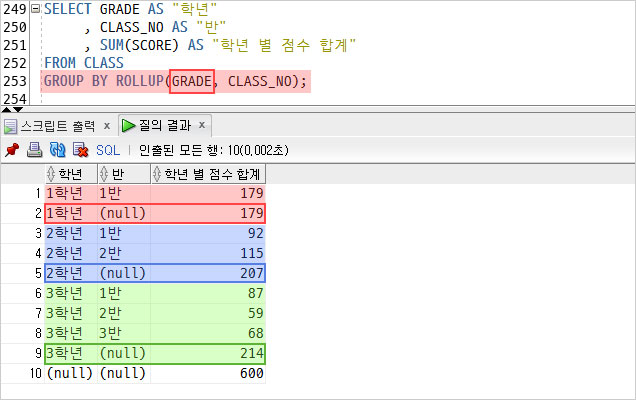
학년, 반으로 GROUP을 지정하고, ROLLUP도 지정했다.
ROLLUP 괄호 안에서 제일 첫번째 그룹의 집계를 함께 조회해주기 때문에
1학년, 각 반의 그룹을 조회하고 총 점수를 출력해주는 걸 볼 수 있다. 순서대로 2학년, 3학년도 바로 아래 각각 조회되었다. 맨 마지막 10번째 행은 1-3학년 모든 학생의 총 점수이다.
CUBE
- 합계 반환
- 모든 조합의 집계 결과 반환
SELECT 컬럼1, 컬럼2, ...
FROM 테이블명
GROUP BY CUBE(컬럼1, 컬럼2, ... 컬럼N);
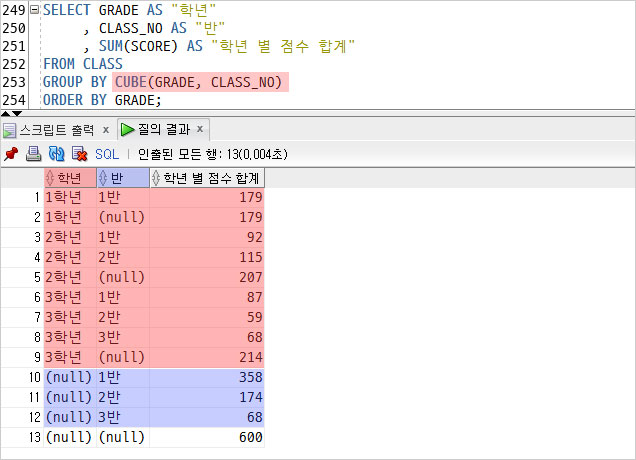
ROLLUP이 첫번째 그룹에 대한 합게를 반환했다면
CUBE는 모든 컬럼 조합의 합계를 반환한다.
조회 결과가 길어져서 두 개의 컬럼만 조회해서 캡쳐했지만..
여러 컬럼을 조회해보면 정말 조합별로 모든 합계를 출력해준다.
집합 연산자
- 여러 개의 조회 결과물을 하나의 쿼리로 만드는 연산자
- UNION / UNION ALL / INTERSECT / MINUS
-
UNION(합집합)
- 여러 개의 쿼리 결과를 하나로 합하는 연산자
- 중복 제거
SELECT 구문
UNION
SELECT 구문;
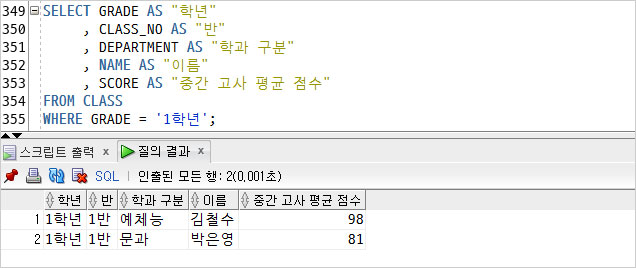
1) 1학년인 학생 조회.
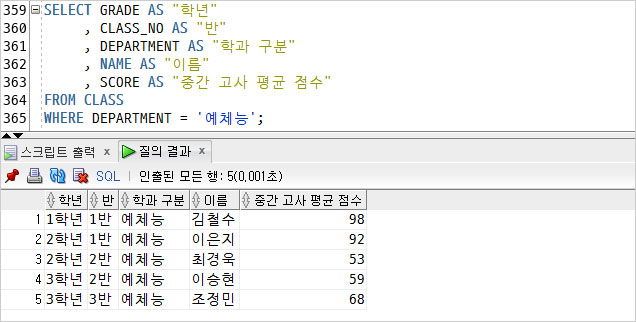
2) 예체능 학과생 조회.
-
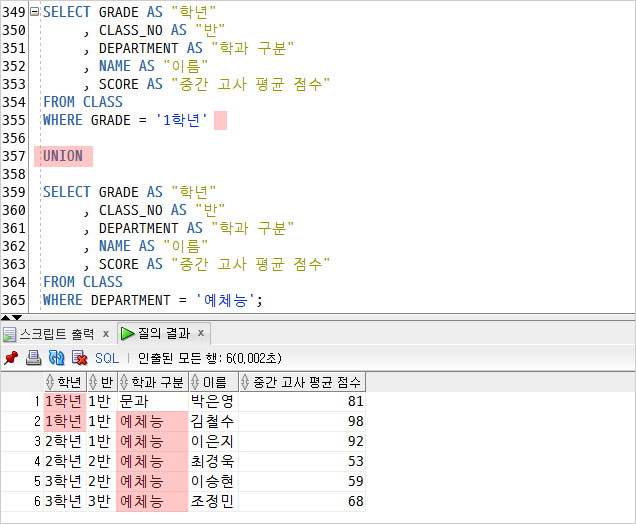
위 두 쿼리문을 UNION을 이용하여 합할 수 있다.
조회 결과를 확인해 보니 이전에 배웠던 OR 연산자와 같은 역할을 하는 것을 알 수 있다.
첫번째 조회 결과는 행이 2개이고,
두번째 조회 결과는 행이 5개이다.
이 둘을 합쳤을 때 7개의 행이 조회 되는 것이 아니라
중복된 행을 제거하기 때문에 6개의 행만 조회되었다.
그리고 첫번째 SELECT문 뒤에 ;(세미콜론)은 삭제해야 한다.
UNION ALL(합집합)
- 여러 개의 쿼리 결과를 하나로 합하는 연산자
- UNION과 다르게 중복 포함
SELECT 구문
UNION ALL
SELECT 구문;
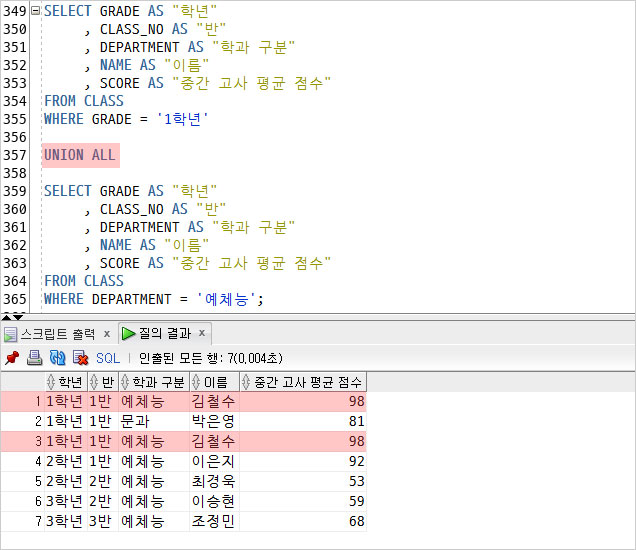
UNION ALL은 UNION과 같지만 중복을 포함한다는 차이가 있다.
중복을 제거 했던 결과와 다르게 김철수 학생의 결과가 2개 조회되어
총 7개의 행이 조회된 걸 확인할 수 있다.
INTERSECT(교집합)
- 중복되는 영역만 조회
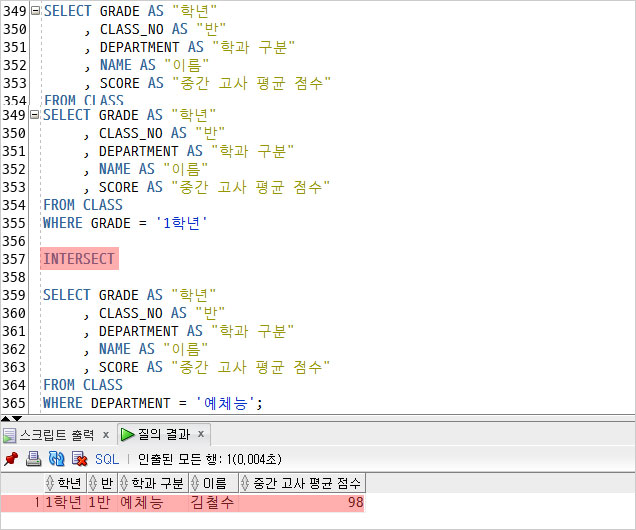
1) 1학년 학생
2) 예체능 학과생인
김철수 학생만 조회되었다.
MINUS(차집합)
- 선행 SELECT 결과에서 다음 SELECT 결과와 겹치는 영역을 제외하고 남은 부분 추출
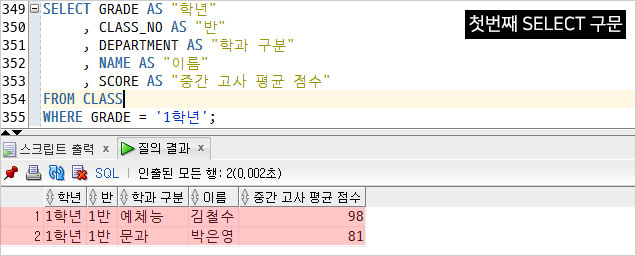
1) 1학년 학생 조회
-
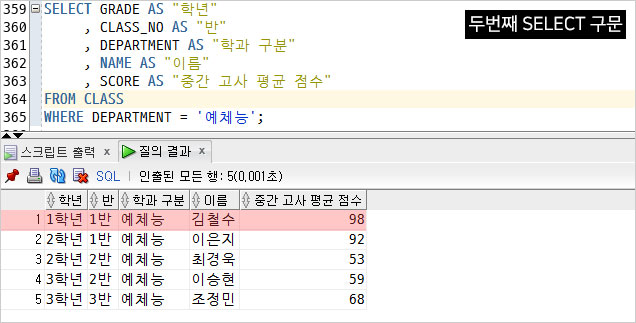
2) 예체능 학과생 조회
-
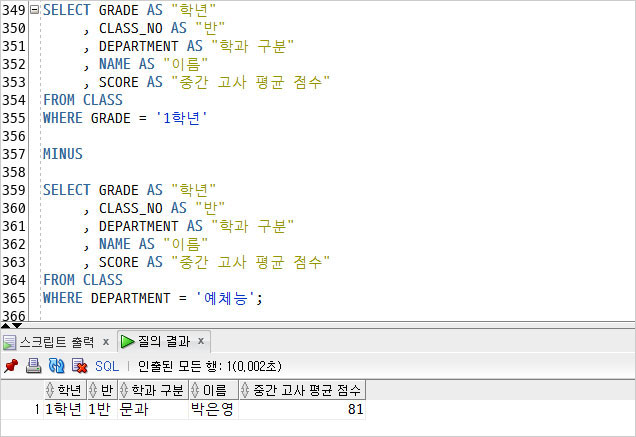
첫번째 조회 결과에서 두번째 조회 결과를 제외시킨다. 해당 되는 행은 김철수 학생의 행이기 때문에 박은영 학생의 행만 조회 된다.
GROUPIN SETS
- 그룹 별로 처리된 여러 개의 SELECT문을 하나로 합친 결과로 조회하고자 할 때 사용
- 집합 연산자 사용과 동일
- 컬럼의 개수와 타입 동일 필수
- 첫번째 쿼리의 컬럼 명으로 조회
SELECT 컬럼명
FROM 테이블병
GROUP BY GROUPING SETS(컬럼1, 컬럼2);
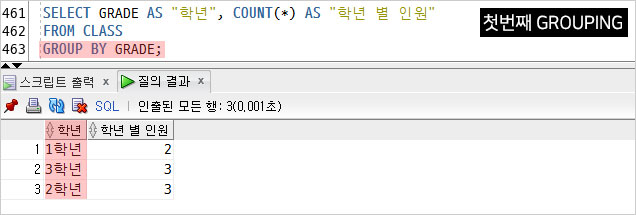
첫번째 조회 결과.
-
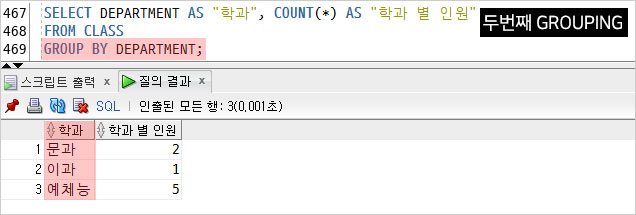
두번째 조회 결과.
-
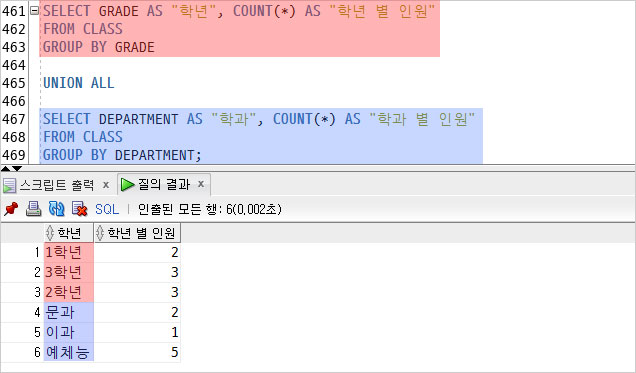
집합연산자를 사용하여 두 개의 결과물을 하나로 합하였다.
이 쿼리문을 줄여서 사용할 수 있는 것이 GRUPING SET이다.
-
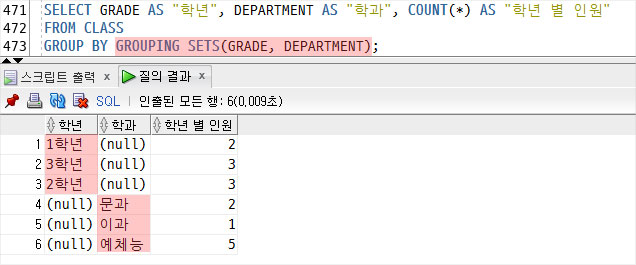
GROUPING SETS를 이용하여
GROUP BY 절에 있던 컬럼을 모두 기술하여 하나의 조회 결과로 합하였다.
코드가 좀 더 간결해졌다.
필요에 따라 사용하면 된다.